Data
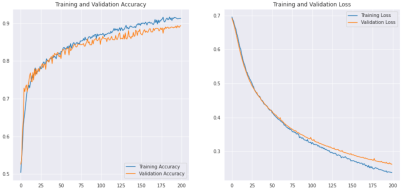
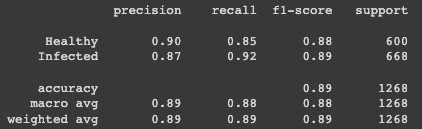
We found a corn leaf infection dataset on the open-source platform Kaggle. It contains images of healthy and infected plants in portrait and landscape formats. There are 14 GB of data, but we resized all of the pictures so we would get a shorter running time. We decreased the photo's width and length to about 12 times smaller than their original size. We have approximately 1000 healthy images and slightly over 1100 infected photos.